Fernerkundung: Informationsgewinnung aus der Ferne

Geodaten haben in den letzten Jahrzehnten eine Schlüsselstellung in der Entwicklung der Informations- und Wissensgesellschaften auf der Welt errungen. Viele Anwendungen, die auf Geodaten aufbauen, bspw. in der Umweltüberwachung, der Nutzung natürlicher Ressourcen, der Verkehrsplanung, der Raumplanung und amtliche Statistiken, besitzen eine große gesellschaftliche und politische Relevanz (Kappas 2012, S. 8 ff). Allerdings stehen nicht immer bereits gesammelte oder aufbereitete Geodaten (zur freien Nutzung) zur Verfügung. In solchen Fällen kann es notwendig sein, eigene Daten zu sammeln, zu kartieren und aufzubereiten. Aber das setzt voraus, dass mensch selbst oder eine beauftragte Person ins Feld geht und die Daten sammelt. Das ist nicht immer möglich oder praktisch umsetzbar, wenn bspw. das Untersuchungsgebiet zu groß ist. Außerdem ist die Ebene der Informationen, die wir sammeln können, auf die Messgeräte beschränkt, tlw. sogar nur auf unsere Augen, die wir mitführen können.
Aus diesem Grund soll dieser Text die Methode der Fernerkundung vorstellen, die es uns erlaubt, Geodaten aus der Ferne zu sammeln und zu analysieren. Mehr noch: Mit der Fernerkundung können wir große Flächen weltweit untersuchen und neue Informationsebenen erschließen, da uns elektromagnetische Strahlung als Informationsübermittler dient. Die Gewinnung von Informationen durch die Fernerkundung hat eine große Bedeutung und wird als Standardverfahren u.a. in der Wetterbeobachtung und im Umweltmonitoring eingesetzt. Damit hat die Fernerkundung auch ein großes Potenzial, die dadurch gewonnen Daten in unseren Kampf für eine bessere Welt einzubringen. Ein Praxisbeispiel, die Klassifikation von Landbedeckungen mit Hilfe von Satellitendaten, soll außerdem zeigen, wie wir die Fernerkundung nutzen können.
Satelliten, Strahlung und Sensoren
Die Fernerkundung ist ein sehr breites Feld, das in seiner Gesamtheit nicht in einem Text zu erfassen ist. Um einen Einstieg zu ermöglichen, möchte ich die Fernerkundung und das Grundprinzip, mit dem Informationen aus reflektierter und emittierter Strahlung gewonnen werden, kurz darstellen.
Was ist Fernerkundung?
Im ersten Schritt möchte ich den Begriff Fernerkundung definieren. Das soll uns eine Eingrenzung dieses sehr weiten Feldes für den Rest des Texts und des Praxisbeispiels ermöglichen.
"Remote sensing is the practice of deriving information about the Earth’s land and water surfaces using images acquired from an overhead perspective, using electromagnetic radiation in one or more regions of the electromagnetic spectrum, reflected or emitted from the Earth’s surface" (Campbell et al. 2022, S. 4).
In der Fernerkundung leiten wir also Informationen über die Erd- und Wasseroberflächen ab, indem wir Bilder nutzen, die aus einer Überkopfperspektive aufgenommen werden. Diese Überkopfperspektive wird durch Sensoren erreicht, die auf Flugzeugen, Satelliten oder Drohnen befestigt sind. Bei der Informationsgewinnung nutzen wir die von den Sensoren aufgenommene elektromagnetische Strahlung, die von der Erdoberfläche reflektiert oder emittiert wird. Das umfasst auch die Strahlung, die für das menschliche Auge nicht sichtbar ist. Das zentrale Konzept ist also klar: Das Sammeln von Informationen aus der Ferne mit Hilfe von elektromagnetischer Strahlung (Campbell et al. 2022, S. 3f; de Lange 2020, S. 431). Damit steht uns eine sehr leistungsfähige Methodik zur Verfügung, aus der Ferne große Flächen in verschiedenen Wellenlängenbereichen des elektromagnetischen Spektrums und Veränderungen im Laufe der Zeit zu beobachten (Campbell et al. 2022, S. 3; de Lange 2020, S. 432).
Elektromagnetische Strahlung und Sensoren
Da nun klar ist, dass wir die von der Erde reflektierte und emittierte elektromagnetische Strahlung zur Informationsgewinnung nutzen, stellt sich die Frage, nach welchem Grundprinzip das funktioniert. Zunächst müssen wir uns klar werden, dass elektromagnetische Strahlung in unterschiedlichen Wellenlängen, abhängig von ihrer Energie, vorkommt. Für die Fernerkundung sind bestimmte Wellenlängenbereiche von besonderer Bedeutung. Zu nennen sind hier das sehr kurzwellige Ultraviolett, das sichtbare Licht, welches unsere Augen sehen können, Infrarot und Mikrowellen, welche Anwendung in Radaren findet. Das Infrarot lässt sich noch weiter unterteilen in das nahe Infrarot, das sich u.a. für die Untersuchung von lebender Vegetation eignet, das mittlere Infrarot, geeignet u.a. für die Untersuchung von Bränden, Mineralien und der Pflanzengesundheit, und das ferne Infrarot, auch Thermal- oder Wärmestrahlung genannt. Die Abgrenzungen sind nicht scharf definiert, mitunter fließend und teilweise auch autorenabhängig (Campbell et al. 2022, S. 28f; de Lange 2020, S. 438). Wichtig ist aber anzumerken, dass nicht alle Wellenlängenbereiche für die Fernerkundung nutzbar sind. Das hängt mit der Durch- bzw. Undurchlässigkeit der Atmosphäre für bestimmte Wellenlängenbereiche, aufgrund von Absorption, Streuung und atmosphärischen Fenstern, zusammen (Campbell et al. 2022, S. 28f; de Lange 2020, S. 440).
Wenn wir nun mit einem Sensor die von unseren Untersuchungsobjekten reflektierte und emittierte Strahlung messen, werden wir feststellen, dass jedes Objekt abhängig von seiner Art, Beschaffenheit und Zustand auf unterschiedliche Weise emittiert oder reflektiert. So werden wir feststellen, dass jedes Objekt ein charakteristisches Strahlungs- oder Reflexionsverhalten besitzt. Das erlaubt uns, sogenannte Reflexions- bzw. Signaturkurven zu erstellen und so Objekte zu indentifizieren (de Lange 2020, S. 431ff). Mit diesem Wissen können wir dann Aussagen bspw. über den Zustand von Vegetation treffen oder Flächen mit ähnlichen Signaturkurven einer bestimmten Landbedeckung zuordnen (de Lange 2020, S. 442ff).
Aber wie funktionieren diese Sensoren, die die elektromagnetische Strahlung messen? Denn wir müssen insbesondere für das Praxisbeispiel bedenken, dass diese keine Bilder wie "normale" Kameras aufnehmen. Jeder Sensor (ein Satellit kann mit mehreren Sensoren ausgestattet sein) wird darauf eingestellt, die eingehende elektromagnetische Strahlung bestimmter Wellenlängenbereiche zu messen. So kann bspw. ein Satellit einen Sensor für das nahe Infrarot und für das ferne Infrarot mitführen. Diese Wellenlängenbereiche, die die verschiedenen Sensoren eines Satelliten messen, werden Kanäle genannt (de Lange 2020, S. 442). Die Daten, die die Sensoren dann liefern, sind wie gesagt, keine Bilder, sondern bestehen für jeden Kanal aus Zahlenmatrizen. Die Werte der Matrizen entsprechen der Einstrahlungsintensität der elektromagnetischen Strahlung am Sensor. Wenn wir nun die jeweiligen Matrizen eines Kanals an einem Bildschirm anzeigen lassen, entstehen Graustufenbilder (de Lange 2020, S. 462f). Bei einer 8-Bit-Farbtiefe steht dann der Wert 0 für die Farbe schwarz und der Wert 255 für weiß. Die Werte dazwischen sind dann entsprechende Graustufen. Wenn wir die Kanäle im sichtbaren Licht, falls entsprechende Sensoren am Aufnahmesystem vorhanden sind, kombinieren, können wir am Bildschirm auch Echtfarbenbilder produzieren.
Neben den Kanälen ist die Auflösung ein wichtiger Parameter bei den Sensoren. Die Auflösung eines Sensors wird in mehreren Kategorien angegeben. Die räumliche Auflösung gibt die Seitenlänge der Pixel an, die der Senor aufnimmt. Die spektrale Auflösung wird durch die Anzahl der Kanäle bestimmt. Die radiometrische Auflösung gibt die Anzahl der Grauwerte an, die zur Verfügung stehen. Üblich sind hierbei 256 Graustufen pro Kanal, was bei der Speicherung 8 Bit notwendig macht. In so einem Fall wird die radiometrische Auflösung mit 8 Bit angegeben. Die temporale Auflösung, oder Repetitionsrate, gibt den Zeitabstand an, innerhalb dessen ein Gebiet von einem bestimmten Sensor wiederholt aufgezeichnet wird (de Lange 2020, S. 443f).
Fernerkundung in der Praxis: Klassifikation von Landbedeckung
Mit dem Wissen, dass fast jedes Objekt eine charakteristische spektrale Signaturkurve besitzt, können wir Untersuchungsansätze entwickeln. Einen Ansatz möchte ich im Folgenden anhand eines Praxisbeispiels vorstellen: Die Klassifikation von Landbedeckungen in einem Ausschnitt von Schleswig-Holstein. Das bedeutet, wir wollen anhand von Fernerkundungsdaten herausfinden, was die vor Ort vorzufindende Landbedeckung ist, ohne die jeweiligen Orte selbst zu besuchen. Diese Daten können dann die Grundlage für weitere Untersuchungen bilden, bspw. über den Anteil versiegelter Flächen oder den Zustand von Vegetation in bestimmten Bereichen. Ich beschränke mich im Folgendem auf die Klassifikation der Landbedeckungen. Für die großflächige Klassifikation von Landbedeckungen eignen sich satellitengestützte Sensoren, die neben dem sichtbaren Licht auch mindestens das nahe Infrarot erfassen, welches die Untersuchung von Vegetation möglich macht (de Lange 2020, S. 436).
Datenbezug
Der erste Schritt wird die Beschaffung von Satellitendaten sein. Anlaufstellen dafür sind natürlich die großen Weltraumbehörden, wie die NASA oder ESA, aber es existieren auch private Weltraummissionen, die kommerzielle Daten zur Verfügung stellen. Freie Fernerkundungsdaten der Landsat- und Sentinel-Missionen finden sich beim USGS Earth Resources Observation and Science Center (EROS) und beim Copernicus-Programm. Ersteres stellt große Mengen an Landsat-Satellitenbildern frei zur Verfügung, zweiteres stellt Daten der Sentinel-Missionen zur Verfügung, welches ein unabhängiges europäisches Erdbeobachtungssystem darstellt. Viele der bei beiden angebotenen Daten sind auch bereits vorverarbeitet, also georeferenziert und können damit direkt im GIS genutzt werden (de Lange 2020, S. 463f).
Für unser Projekt werden wir Daten der Sentinel-Satelliten der Copernicus-Mission nutzen. Das Ziel dieser Mission ist, Datengrundlagen für die Land- und Forstwirtschaft, Landmanagement, Gewässerüberwachung, Katastrophenschutz, Klimawissenschaft u.v.m zu liefern (Campbell et al. 2022, S. 182; de Lange 2020, S. 459). Im speziellen werden die für das Projekt verwendeten Daten vom Satelliten Sentinel-2A kommen. Sentinel-2A ist nämlich mit einem hochauflösenden multispektralen Sensor ausgestattet, der u.a. blau, grün, rot und infrarot mit einer Auflösung von 10 Metern misst (de Lange 2020, S. 459). Damit erscheint Sentinel-2A gute Voraussetzungen mitzubringen, um Landbedeckungen zu klassifizieren. Insbesondere da auch infrarot gemessen wird, was für die Untersuchung von Vegetation gut geeignet ist.
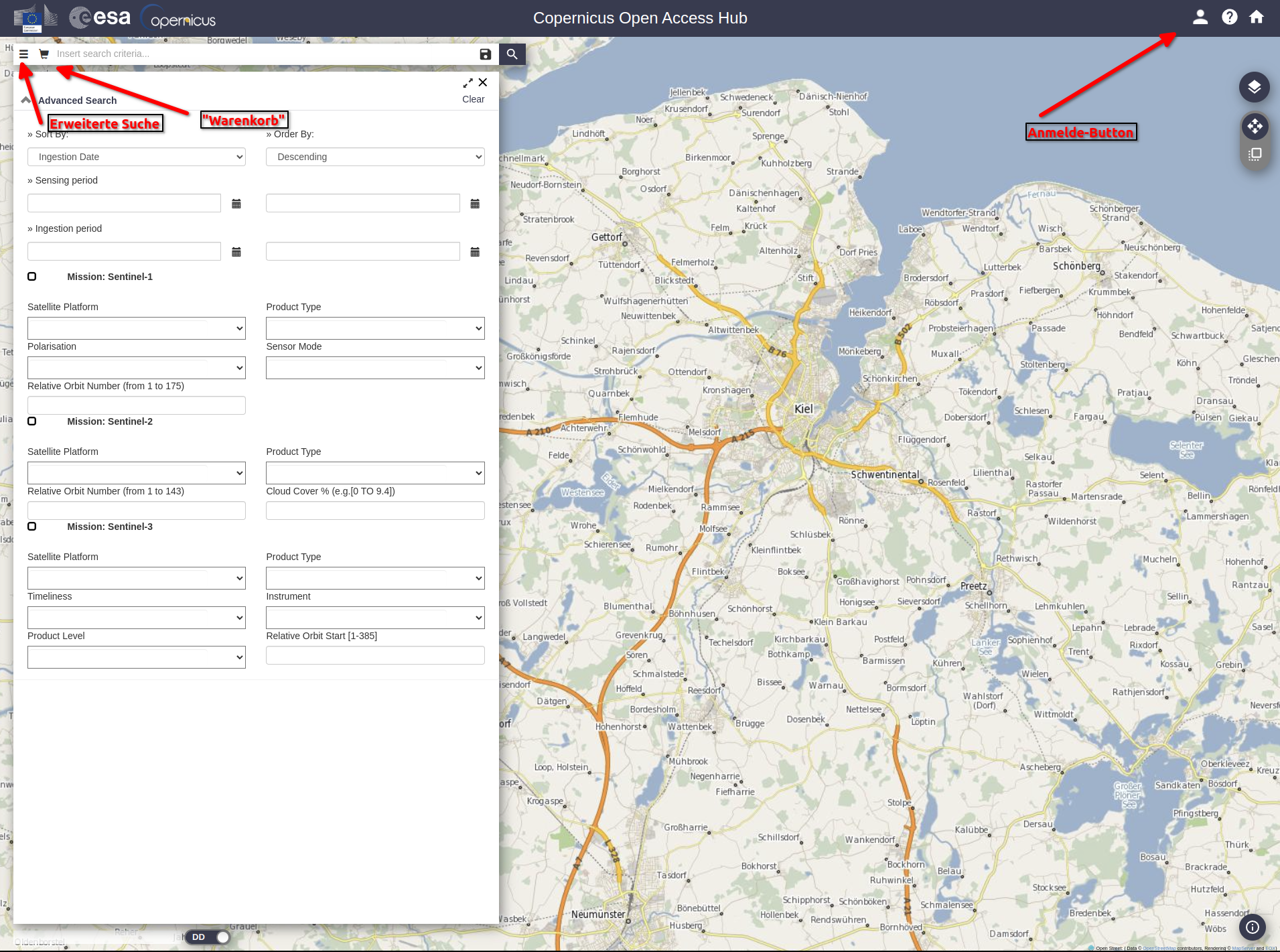
Satellitendaten der Sentinel-Satelliten können wir vom Copernicus Open Access Hub herunterladen. Es gibt mittlerweile ein neues Copernicus Data Space Ecosystem, der Open Access Hub ist aber noch funktionstüchtig. Die Bedienung des Open Access Hub ist allerdings etwas kompliziert. Es benötigt erstmal einen Account. Dieser lässt sich mit einem Klick oben rechts auf das Kopfsymbol erstellen. Danach lässt sich direkt nach sogenannten Szenen suchen. Wenn mensch die genaue Bezeichnung einer Szene nicht weiß, lässt sich mit Rechtsklick auf die Karte ein Polygon zeichnen. In Verbindung mit der erweiterten Suche, die sich über die drei Striche im Suchfeld erreichen lässt, lassen sich Szenen nach ausgewählten Kriterien im Bereich des vorher gezeichneten Polygons suchen. Wenn mensch dann eine Szene gewählt hat, ist diese im "Warenkorb" (Einkaufswagensymbol) zu finden und herunterzuladen. Für unser Praxisbeispiel nutzen wir die Szene "S2A_MSIL2A_20200623T103031_N0214_R108_T32UNF_20200623T142851". Diese erstreckt sich über den Nordosten Schleswig-Holsteins und Südosten Dänemarks und stammt aus dem Juni 2020.
Vorbereitung der Daten
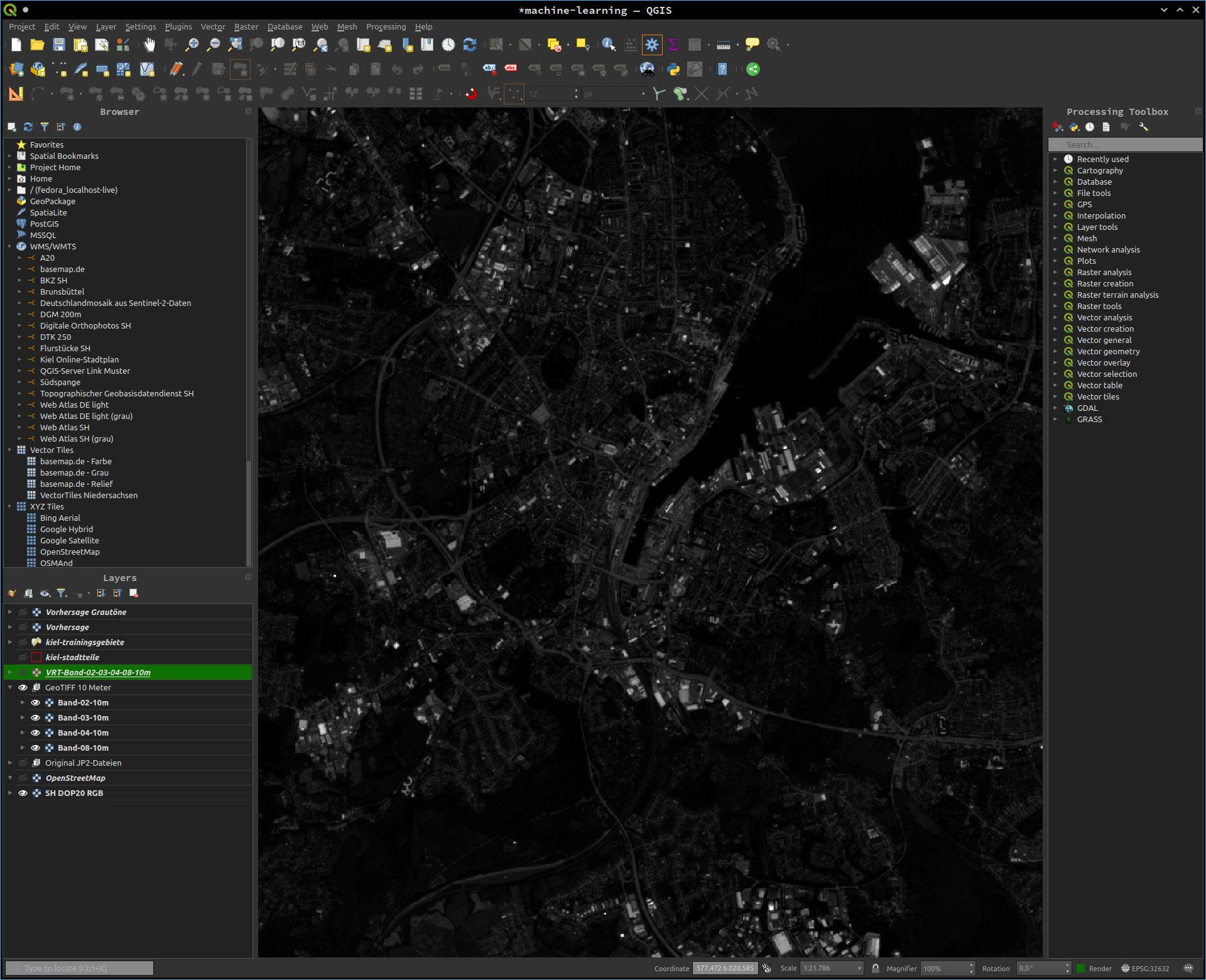
Sind die Daten heruntergeladen, können wir diese direkt ins GIS laden und uns mit diesen vertraut machen. Die "MTD_MSIL2A.xml" bietet uns bereits verschiedene Variationen aus Echtfarben- und Falschfarbenbildern. Für unsere nächsten Schritte laden wir die Bilddaten für die Bänder 2 bis 4 und Band 8, die sich als jp2-Dateien unter "Projektordner/GRANULE/L2A_T32UNF_A026131_20200623T103426/IMG_DATA/R10m/" finden lassen, ins GIS und exportieren diese dann als GeoTiff-Dateien. Diese Tiff-Dateien werden später vom Skript genutzt, dass die Klassifikation durchführt. Als Ergebnis sehen wir zunächst Graustufenbilder. Jede Rasterzelle beinhaltet den Wert, den der Sensor an der jeweiligen Stelle für den jeweiligen Kanal gemessen hat.
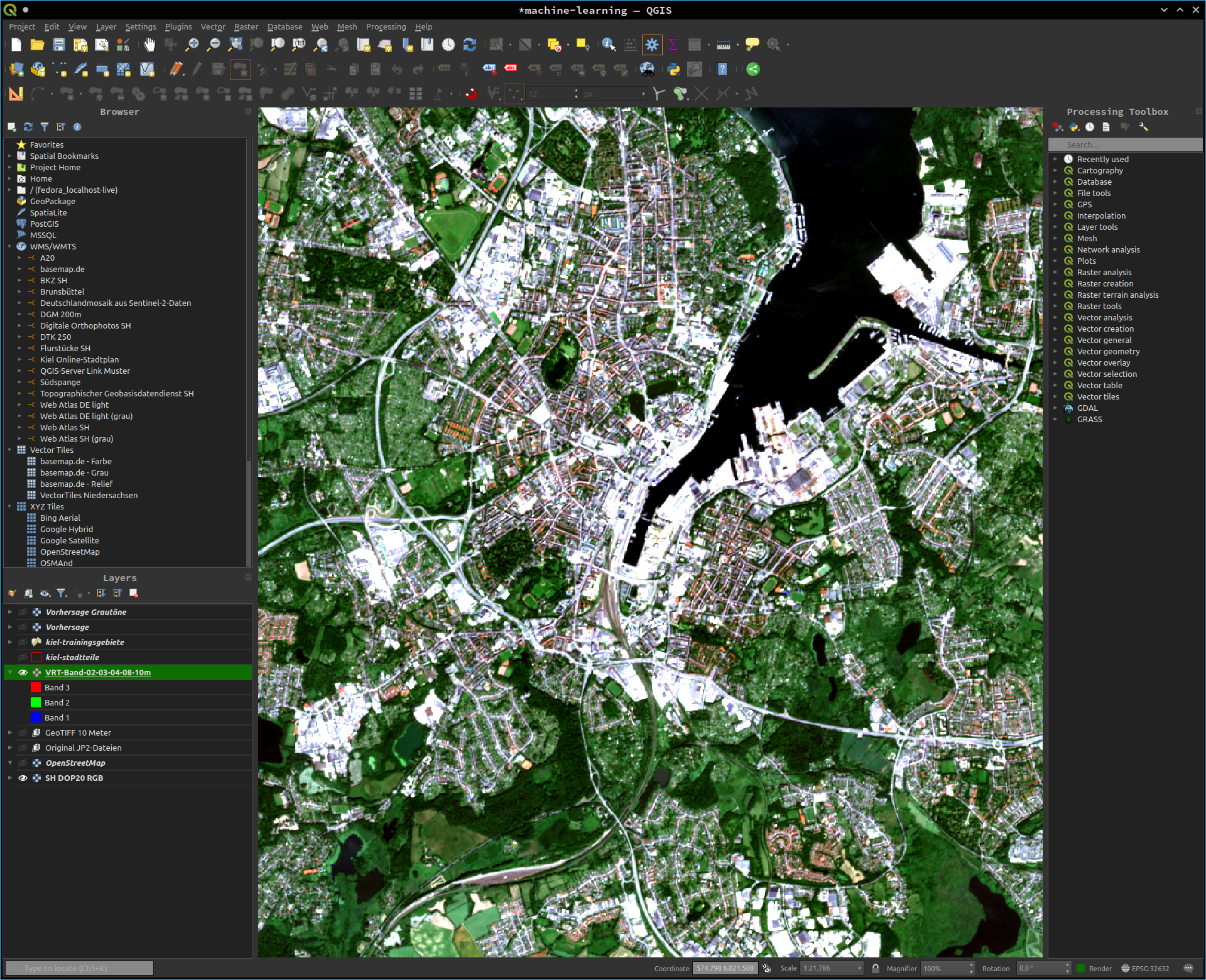
Aus den Tiff-Dateien können wir nun ein virtuelles Raster als Echtfarbenbild generieren. Dafür müssen wir in den Eigenschaften des virtuellen Rasters den Render type auf Multiband color einstellen und die jeweils richtigen Bänder zuweisen. Es lassen sich auch die im Datensatz vorhandenen Echtfarbenbilder nutzen. Diese Echtfarbenbilder nutzen wir im weiteren Verlauf, um Klassen und Trainingsgebiete festzulegen.
Festlegen von Klassen und Trainingsgebiete
In diesem Text fielen bereits die Begriffe Klassifikation, Klassen und Trainingsgebiete. Doch was haben diese mit dem Ziel, Landbedeckungen in einem ausgewählten Bereich der Erde herauszufinden, zu tun? Die Satellitendaten, die uns vorliegen, bestehen aus Pixeln, die alle unterschiedliche Werte, und damit Eigenschaften, haben. Das Ziel ist, alle Pixel, die ähnliche Eigenschaften haben, einer jeweiligen Landbedeckungsart zuzuordnen, sprich zu klassifizieren. Denn es ist generell davon auszugehen, dass die verschiedenen Landbedeckungsarten eigene, für sie charakteristische Reflexionsverhalten haben (de Lange 2020, S. 483ff).
Zuerst legen wir Klassen fest. Dies sollen die Landbedeckungen sein, die wir erwarten oder hoffen, zu finden und zu klassifizieren. Als Hilfsmittel dient hier das generierte Echtfarbenbild. Anhand dessen können wir Landbedeckungen, die wir in diesem sehen, als Klassen festlegen. Kritierium sollte dabei sein, dass diese auf dem Bild homogen aussehen. Anhand dieser Voraussetzungen habe ich folgende Klassen festgelegt:
- Wasser für Wasserflächen
- Industrie und Gewerbe für Industrie- und Gewerbegebiete
- Straßen für Straßen, Parkplätze und andere große Plätze
- Bahn für Bahnanlagen bzw. Bahnschienen
- Wald für Wälder und Baumgruppen
- Gebäude für alle Gebäude, die nicht Industrie oder Gewerbe sind
- Landwirtschaft für landwirtschaftlich genutzte Flächen
- Grünflächen für Grünflächen, die nicht landwirtschaftlich genutzt werden oder Wälder sind
- Sportanlagen für Sportanlagen und Laufbahnen
- Kleingärten für Kleingartengebiete
Der nächste Schritt ist die Festlegung von Trainingsgebieten. Dafür zeichnen wir im GIS mehrere Polygone für jede Klasse. Da wir das Echtfarbenbild als Hintergrund nutzen können, sollte dies einfach von der Hand gehen. Ist das erledigt, können wir zum nächsten Schritt übergehen, in welchem wir jeder Fläche einer Landbedeckung zuordnen werden.
Klassifikation mittels maschinellen Lernens
Die folgende Klassifikation der Satellitendaten lassen wir ein Python-Skript übernehmen. Dieses wird mittels maschinellem Lernen automatisiert alle Pixel einer der vorher definierten Klassen zuordnen. Klassifikationsverfahren, die dem maschinellen Lernen zuzuordnen sind, sind mittlerweile zum Standard geworden (de Lange 2020, S. 496). Für unser Praxisbeispiel habe ich mich für den sogenannten Random-Forest-Classifier als Klassifikationsverfahren entschieden.
Es sind allerdings Einschränkungen bei der automatisierten Klassifizierung von Landbedeckung zu beachten. Die Signaturkurven von Objekten können sich je nach Jahreszeit oder Atmosphärenzustand ändern, sodass mensch nicht von allgemeingütligen Signaturkurven ausgehen kann. Außerdem setzen die geometrische und spektrale Auflösung der Sensoren bei der Erkennung von Mischformen von Klassen Grenzen (de Lange 2020, S. 443ff).
Ein ausbaufähiges Ergebnis
Wenn das Skript erfolgreich durchgelaufen ist, erhalten wir eine Rasterdatei als Ergebnis zurück, in welchem jedes Pixel die ihm zugeordnete Klasse enthält. In dem dargestellten Ausschnitt des Untersuchungsgebiets (Kieler Innenförde) sind die Strukturen, wie sie auch in der Realität zu finden sind, gut zu erkennen.

Entsprechend ihrer Klasse lassen sich jedem Pixel Farbwerte zuordnen. Daraufhin erkennen wir schonmal grob die Siedlungsstrukturen, die Wasser- und Grünflächen und Verkehrswege rund um die Innenförde.

Nun gilt es anhand von Orten, die mensch kennt, zu beurteilen, ob das Klassifikationsverfahren valide Ergebnisse hervorgebracht hat. Dabei stechen einige auffällige Fehler hervor, die das Gesamtergebnis schmälern. Zum einen wurden Küstengewässer tlw. falsch klassifiziert und als Industrie- und Gewerbegebiete erkannt. Außerdem wurden landwirtschaftlich genutzte Flächen als Sportanlagen klassifiziert.

Zum anderen sticht eine große Fehleinschätzung der Klassifikation bei den Wäldern hervor. In größeren Waldgebiete wurden diese nämlich als Gebäude klassifiziert.

Weitere Fehlklassifikationen lassen sich u.a. bei Kleingartengebieten finden, die mal als Grünflächen, Gebäude oder landwirtschaftlich genutzte Flächen falsch erkannt wurden. Doch wie gehen wir mit diesen Fehlern um?
Nächste Schritte
Die aufgetretenen Fehlklassifikationen zeigen, dass Handlungsbedarf besteht. Es bestehen grundsätzlich mehrere Möglichkeiten, mit den Fehlern umzugehen. Zum einen ist das eine Änderung der Trainingsgebiete, in der Hoffnung, dass die Klassifikation daraufhin besser funktioniert, zum anderen ist das eine Veränderung der zu klassifizierenden Klassen. In meinen Augen erscheint in unserem Praxisbeispiel die folgende Anpassung der Klassen am sinnvollsten:
- Wasser für Wasserflächen
- Straßen für Verkehrsflächen, Straßen, Parkplätze und andere große Plätze
- Bahn für Bahnanlagen bzw. Bahnschienen
- Wald für Wälder und Baumgruppen
- Gebäude für alle Arten von Gebäuden
- Landwirtschaft für landwirtschaftlich genutzte Flächen
- Grünflächen für Grünflächen, die nicht landwirtschaftlich genutzt werden oder Wälder sind
Bei diesem Vorschlag ändert sich zum einen, dass es keine Unterscheidung zwischen "normalen" Gebäuden und Industrie und Gewerbe gibt. Eine Unterscheidung erscheint hier nicht sinnvoll. Die großen Flächen, die Industriegebäude oft umgeben, bspw. Parkplätze, sollen der Klasse "Straßen" zugeordnet werden und entsprechend in den Trainingsgebieten berücksichtigt werden. Zum anderen wird die Klasse Kleingärten entfernt. Diese bestehen oft aus einer Mischung von Gebäuden (Lauben, Schuppen) und Grünflächen. Entsprechend wurden Kleingartenflächen auch kaum als diese klassifiziert. Tlw. wurden sie sogar als landwirtschaftlich genutzte Fläche identifiziert. Ein Entfernen der Klasse soll dafür sorgen, dass die Gärten als Grünflächen und die in ihnen liegenden Gebäude als Gebäude klassifiziert werden. Eine genaue Identifikation von Kleingärten mit eindeutigen Signaturkurven ist aufgrund der beschriebenen Mischungen nicht möglich. Außerdem entfällt die Klasse Sportanlagen. Da ich eine Unterscheidung zwischen Rasenflächen von Sportanlagen und "normalen" Grünflächen im ersten Durchgang als unrealistisch gesehen habe, hatte ich bei den Trainingsgebiete sowieso nur Laufbahnen und Tennisplätze berücksichtigt. Da landwirtschaftliche Flächen mit Sportanlagen verwechselt wurden und Sportanlagen von ihrer Anzahl vernachlässigbar erscheinen, würde ich diese als eigene Klasse nicht mehr berücksichtigen.
Wenn wir diese Änderungen durchgeführt haben, können wir das Skript nochmal durchlaufen lassen.
Die Ergebnisse des erneuten Durchlaufs werden Thema eines weiteren Blogpost sein. Das Python-Skript soll unter einer freien Lizenz veröffentlicht werden. Ein Zeitpunkt ist aber noch nicht absehbar, da es dafür Anpassungen des Codes bedarf.
Literatur
Campbell, J. B.,Wynne, R. H. und V. A. Thomas (2022): Introduction to Remote Sensing. 6. Auflage. New York. de Lange, N. (2020): Geoinformatik in Theorie und Praxis. 4. Auflage. Berlin/Heidelberg. Kappas, M. (2012): Geographische Informationssysteme. 2. Auflage. Braunschweig.